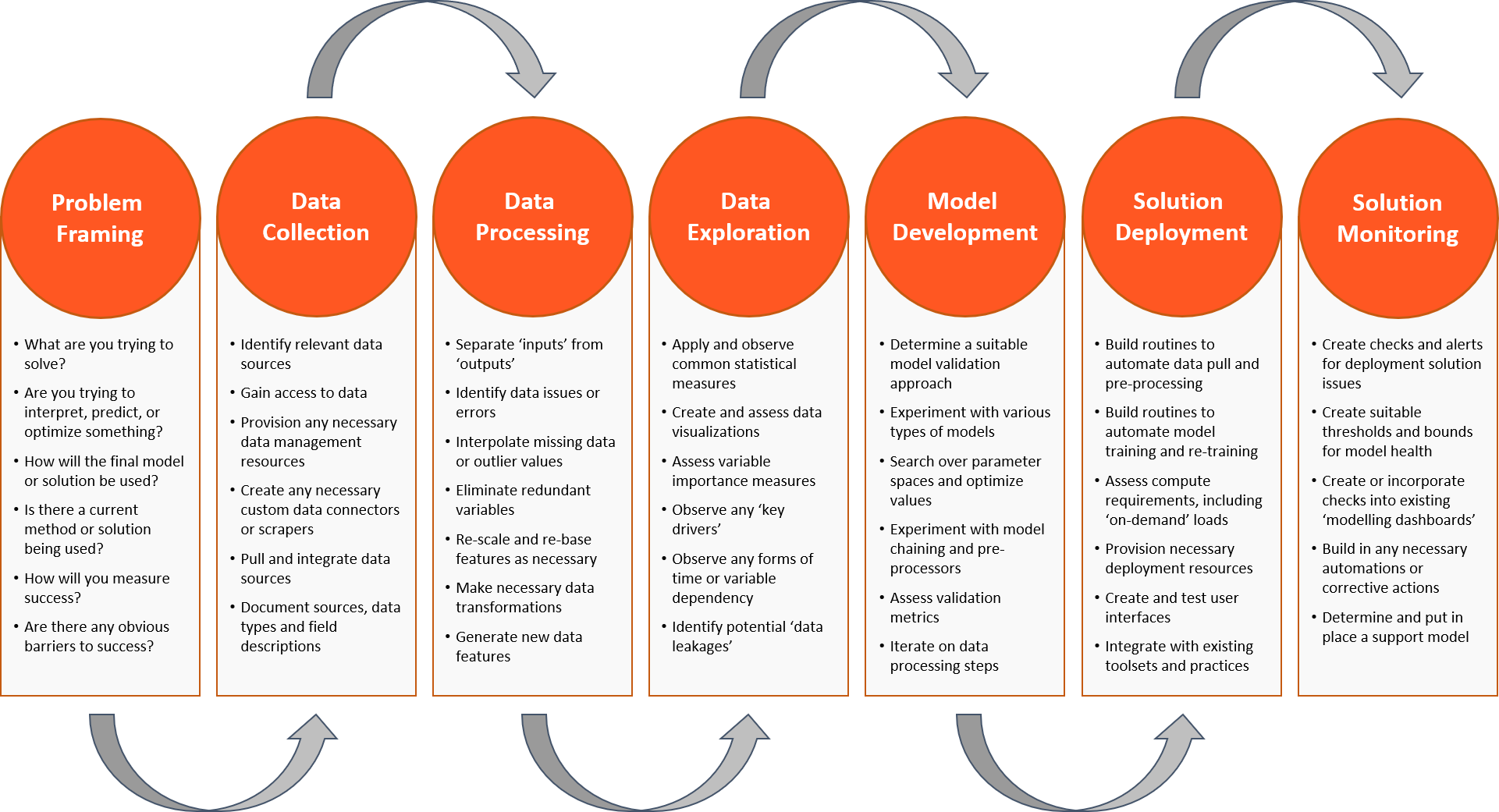
The data science workflow involves more than just fitting models. The problem needs to be framed, data obtained and prepared, and then there is still a piece of work around deploying the solution for use.
What are you trying to solve?
Are you trying to interpret, predict, or optimize something?
How will the final model or solution be used?
Is there a current method or solution being used?
How will you measure success?
Are there any obvious barriers to success?
All data science efforts should start with problem framing. It’s a critical, but often neglected step in the process. But understand that this is the time to set the right foundations for what you would like to achieve, as well as identify and avoid any barriers to success.
What are you trying to solve?
Starting an advanced analytics effort without understanding what you want to achieve is a recipe for disaster. You may spend countless hours working towards something that simply cannot be achieved based on available data, techniques or resources. So start by thinking through what you are trying to solve. Do you want to simply understand something better using data (inference), do you want to be able to determine an answer given a set of inputs (prediction), or do you want to control a set of inputs in order to achieve a goal (optimization)?
How will the solution be used?
And that’s not the only consideration you need to make before getting started. You need to think through how the solution is intended to be used. Do you need something that works in an automated fashion, or should it provide recommendations for someone to interpret and act on? Is it a one-time exercise, or does the solution need to be deployed and made available for ongoing use? Or maybe there’s an existing, and potentially complex, business practice that the solution needs to be incorporated into? Does the solution need to feed and interact with an existing system? Does it require a change in behavior, change in culture, or for users to overcome a bias in thinking?
How will you measure success?
You also need to determine some criteria up-front on what success (and failure) looks like. A lot of people promote the fail-fast philosophy, but don’t set any expectations as to what outputs should be achieved, and by when. There needs to be some initial view of how to determine success. And while it can be loose, particularly when approaching something completely new or using experimental methods, it’s still important to keep a view of this initial criteria.
Identify any obvious barriers now
The point of this exercise is to not only appropriately scope and tackle the effort. But to also identify any obvious barriers to success. And it may not even be possible to overcome these barriers. Issues such as a lack of relevant data or an inability to deploy a useable solution based on a current available infrastructure, are both examples of barriers which should be identified and overcome before any effort is made on developing the solution.
Once you understand your problem, it’s time to collect the data. Don’t skim over this step. The quality of any analytical model or solution is highly dependent on the quality and variety of its data sources.
Identify relevant data sources
Collecting data starts with identifying data sources. If you are struggling to make a step here, then think through what problem you are trying to solve and what data could be relevant. Your problem should have a domain area and context which you can leverage to help identify relevant sources. Are you trying to predict real estate prices for example? Then you will likely need historical prices, property types, locations, build dates, economic indicators and so forth… Are you trying to predict individual credit scores? Then you’ll no doubt want data on their payment history, current debt levels, current level of income, and so forth…
Gain access to the data
Once you know what data you need, it’s time to get access. That may be as simple as connecting and querying a single data table, or it might require identifying and sourcing data from hundreds of separate sources and providers. As a quick hint, find and give preference to providers who offer a modern way to directly query and pull their data. It will make deployment of your solution that much easier. And be aware that the data you need might not be freely available. Data is valuable, and there is every chance that you’ll need to pay to access quality data for your problem.
Pull and integrate
Once you have identified and gained access to your data sources. It’s time to pull and integrate that data. If you are working with a relatively small dataset, it may be feasible to collate your data into a single dataframe. Otherwise, you may need to build a light schema around your collected data so each source can be related together. This step will largely come down to the context of your problem, as well as what method you are targeting. So keep a view of how you intend to ultimately use the data as you make your integrations. And while it’s important to build a consolidated view, try to avoid making unnecessary data duplications.
Document what you use!
Don’t ignore building a solid data dictionary. The data collection step is the perfect time to put some proactive effort towards recording the source, field descriptions, unit of measures, existing schemas, as well as any embedded data transformations. It’s a critical step that will not only benefit the current effort, but also future efforts which may have line of sight to using similar data.
Identify relevant data sources
Gain membership to data
Provision any necessary data processing resources
Create any necessary custom data connectors or scrapers
Pull and integrate data sources
Document sources, data types and field descriptions
Separate ‘inputs’ from ‘outputs’
Identify data issues or errors
Interpolate missing data or outlier values
Eliminate redundant variables
Re-scale and re-base features as necessary
Make necessary data transformations
Generate new data features
Now that you have identified, sourced and collated your data sources, it’s time to get that data into a format where it can be used. This can be one of the most painful and exhausting steps in the workflow, particularly when working with poor quality data. But chin up, spending the effort on processing your data correctly will pay off once you come to apply your analytics techniques.
Separate the in’s from the out’s
Before you even touch the data. Make sure you have identified your inputs versus the outputs. For a prediction problem, your output is what you are trying to predict (referred to as a label) and the inputs are what you’ll use to predict it (referred to as features). And you need the historical examples of what the label was for a given set of features, so you can derive a model capable of prediction. However, it’s important you do this before starting any data processing. As typically, you will not want to apply processing to the label value. Of course, there are exceptions, but it’s still important either way to understand the in’s from the out’s.
Identify data issues or errors
As a next step, start looking for any obvious data issues or errors over your features. Inconsistent data formats and missing values will be the easiest to identify. However, the more difficult and potentially subjective errors are those of outlier values. What constitutes an outlier? How do you know it isn’t a legitimate data point containing information on an extreme event? Statistical and visualization methods come into play here. Quartile values, data point counts, missing value plots, distribution plots… These are all methods which can be used to help identify low-hanging fruit when it comes to identifying data issues or errors.
So you found issues, now what?
Every data problem requires some level of judgement on how to correct it. And this is one of the first steps where bias can be introduced, so tread carefully. Take the example of missing values over a variable. You could, drop all the rows where that variable has a missing value, drop the variable entirely, or you could interpolate its missing values. The decision is going to need to membership for, amongst other things, what the variable represents, how important you believe it to be, and how many missing values it has. And if you decide to interpolate those missing values, what method will you use? Think through and document your decisions carefully.
Data transformation and feature generation
Data transformations and feature generation is another important step in data processing. Feature scaling being a common example. If you have a set of features within a numeric range of 0-100, but one feature which within the millions, then you may want to scale that feature so that it lies within the common space. And then there’s feature generation, where you take a single feature and derive multiple new features from it. Text based fields are a common example, where you can tokenize words in the field to create a new set of separate binary features.
Now that you have a consolidated and processed view of your data, it’s time to start exploring. You may have already used some of these techniques over the previous steps, but now your goal is different. You want to start extracting insights from the data relevant to your problem. These insights may be used directly, or you may use them to shape how you approach the next steps.
Start with common statistical measures
Perhaps the easiest place to start is generating statistical measures over your dataset. You may even be in a position to extract these ‘summary metrics’ over your entire dataset in a painless and automated way. Measures of a variable's average, most frequent values, number of missing values, percentiles, and variance, are most common. But also look at measures of correlation and covariance between pairs of variables. Particularly between the input features and output label for prediction problems.
Create and assess data visualization
Data visualizations are critical towards data exploration. A properly crafted visualization can expose powerful insights that can often get lost in the mountain of statistical measures. At a variable level, you have two main options here. Univariate plots, which are visualizations characterizing a single variable. Distributions and box-and-whisker plots are common ground here. But you also have bivariate or multivariate plots, which are plots characterizing the relationship between a collection of variables. In this case, scatter plots are common ground, where you can apply categorizations and overlays to capture more than two variables.
Observe key drivers and dependencies
As mentioned, your goal for data exploration is to start extracting relevant insights to your problem. Look for pairs of variables which have a high level of correlation to start with. For prediction problems, pay particular attention to those input features which have a high correlation with your output target. These may constitute your ‘key drivers’, and provide your best bet towards being able to form an accurate prediction. And don’t miss out on time dependencies here either. It may be that there is a time lag between a change in one of your features and the output label, which is something that can be accounted for by creating lagged versions of your features.
Beware of data leakages
Data leakages are toxic, and it’s not an uncommon problem for inexperienced data scientists. Fortunately, the data exploration step provides a great opportunity to avoid this issue moving forward. In its simplest form, and when dealing with a prediction problem, leakage is caused by including features which are in-fact representations or directly derived from what you are trying to predict. Remember, it’s inputs versus output. Not output versus output. But note that this isn’t the only time you’ll need to be aware of leakage. It’s also something to look out for as part of the model development process which we will cover next.
Apply and observe common statistical measures
Create and assess data visualizations
Assess variable importance measures
Observe any ‘key drivers’
Observe any page of time or variable dependency
Identify potential ‘data leakages’
Determine a suitable model validation approach
Experiment with various types of models
Search over parameter spaces and optimize values
Experiment with model chaining and pre-processors
Assess validation metrics
Iterate on data processing steps
You should now have a firm grasp on your dataset and have made any necessary data pre-processing steps. So it’s finally time to work through the model development process.
How will you validate your model?
Understanding the method of validation is the most important part of the process. In general, this step includes all aspects of how you will assess your model’s performance. And it starts with how you intend to make a separation between training and test sets of data. Note that the training set is used by the model to learn and the test set is used to assess how well it has learnt. Make this choice wisely, as having too much training data won’t leave enough test data, leading to an ‘overfitted’ model. While having too much testing data won't leave enough training data, leading to a poorly performing model. But that’s not all. You’ll also need to select appropriate metrics in order to assess your model. Will you look at model accuracy, a more direct measure of error, precision... The list goes on.
Start trying different model types
This is where things can really start to get interesting. You can now start to try out a variety of types of models for your problem. Obviously, there will be certain classes of models which you should focus on depending on the problem type. But for prediction problems, the machine learning world offers a huge range of model types. Decision trees, Random Forests, Support Vector Machines, Neural Networks and the list goes on. There are ways to automate the selection process, but you’ll no doubt want to introduce some experimentation here too.
Optimize the parameters
‘Tuning’ a model involves varying its parameter values in order to improve its performance. And each type of model will have a particular set of parameters which can be used to vary its performance. What you need to observe here, is that varying these parameters can often influence the ‘complexity’ of the model. Or in other words, how well it is able to fit and learn the data. But keep in mind, there are often no free lunches here. You’ll need to weigh training set performance against test set performance. And in some cases, it may pay to use parameter values which constrain the complexity of the model, so that it is able to perform well over the test set and future sets of data.
Iterate on previous steps
Did we mention this is all an iterative process? You will no doubt want to go back and review the data processing steps are part of developing your model. If you interpolated missing values, try and vary the method. If you identified and eliminated outlier values, try and revisit the criteria. If you dropped certain features, try and add them back in. Feature generation in particular, can be a great step to iterate on as you look to experiment with model development.
If you’ve made it this far, you should give yourself a pat on the back. You have framed your problem, sourced and processed the data, and have managed to develop a model which has met your validation criteria. Now it’s time to deploy your solution so it can be used.
Routines to automate data and modelling steps
Think about all the previous steps in the workflow. You no doubt took for granted how much manual decision making and input went into those steps. But now it’s time to automate the process. If you are working on a robust analytics platform, this step may be somewhat trivialized. But if not, you will need to create the necessary scripts, routines, loops and jobs in order to run your end-to-end workflow in an automated fashion. This will likely be much more of a data engineering task than a data science task. But being able to productionize workflows is critical towards having your insights put into action.
Assess and provision the necessary resources
The resources you used to build your workflow are no doubt going to be different than those you use to deploy it. You may need resources which can offer edge compute, redundancy, remote membership, scheduling, and a processing layer for those orchestrating resource use. Cloud platform providers, such as Microsoft Azure, Amazon AWS, and Google Cloud all have fantastic offerings in this area, providing a huge amount of flexibility in what resources you create, where you create them, and how they are used.
You might need a user interface
How will your model be used? Will it have autonomous control over something, or will you provide a user interface for someone to consume and act on your model insights? For the later case, the user may also need to see more than just the model outputs. They may want to see a summarized view of ‘how’ the model has derived its output. Including what features contributed most towards the result, what the model’s latest training and test performance looks like, and whether any issues were encountered throughout the workflow chain.
Integrate into existing practices
A Data Scientist will no doubt have complete faith and trust in their model. They made it at the end of the day. But don’t expect that will instantly translate into the model being used and adopted. If there is a human component involved in interpreting and using the model's insights, then there no doubt is going to be an existing practice which needs to be identified and adapted. The whole change management and cultural aspect of data science can come into play here. So don’t underestimate the importance of this step towards reaching success.
Build routines to automate data pull and pre-processing
Build routines to automate model training and re-training
Assess compute requirements, including ‘on-demand’ loads
Provision necessary deployment resources
Create and test user interfaces
Integrate with existing toolsets and practices
Create checks and alerts for deployment solution issues
Create suitable thresholds and bounds for model health
Create or incorporate checks into existing 'modelling dashboards'
Build in any necessary automations or corrective actions
Determine and put in place a support model
So the solution has been deployed, but who is monitoring it? How can we be sure it’s still providing valuable recommendations? And who is going to step in if something goes wrong? We are now well and truly in the data engineering world, and many of these steps are going to extend beyond the role of the Data Scientist. But getting this right will make sure the workflow remains working and valid not just when it’s deployed, but also well into the future.
Checks and alerts
Part of ensuring that the solution remains up and running is to put the necessary checks and alerts in place if something goes wrong. And some of the workflow components may even be outside of your control. The obvious ones being around data connections and consistency of the data. So focus on creating checks and alerts to detect these issues first. But also keep in mind that some issues may not break the workflow. So it’s important to do the what-if analysis, and to be thorough towards identifying and creating alerts for even the more subtle problems.
Model health is part of this
Checks need to be put in place for more than just the deployment components. Model health also needs to be considered. You have a model producing insights based on new data, and it may be re-training based on that new data. But how are you making sure that the model doesn’t drift and the results stay within an acceptable level of accuracy?
Not everything needs to be manually corrected
Remember, not every problem needs to be handled manually. For example, you could put a threshold and alert in place on your model performance metric and manually intervene. Or, another method could be to build in the logic to allow your workflow to adjust and adapt to performance issues automatically. One option may even be to revert between model types in an automatic fashion, via an ongoing ranking system of model types, where the superior model is selected and used for a given period.
A support model is critical
All of this needs some form of support model. Resources for various types of problems and criticality need to be identified so you are prepared if an issue occurs. Keep in mind that there is separation between a data engineering issue and a data science issue, and not all modelling issues need to be addressed by data science resources. So it’s important to make sure that problems are passed and actioned by the right resource.