Many of the businesses we work with have faced the dark side of Excel. A side which comes in the form of bloated and unsustainable Excel monster-books.
Here at Datakick Analytics, we regularly work with businesses who make heavy use of Microsoft Excel for their data needs. They maintain hundreds if not thousands of workbooks which handle everything from data entry to analysis. And it's not surprising, with many businesses citing the transparency and ease Excel offers for sharing workflows, the broad level of acceptance and adoption Excel has across the organization, and the flexibility and power Excel's built-in functions and formula can provide.
The dark side of Excel
But there's also a dark side to Excel, which comes in the form of bloated and unsustainable Excel monster-books. You know the type. They're tens of megabytes in size and Excel will often scream out in pain whenever you change a single cell. These workbooks are riddled with static data dumps, complex formula, VBA macros, and multiple third-party connectors. And worse yet, only one or two analysts within the organization know how to use and maintain them.
And while the ideal solution may be to adopt a set of more suited and dedicated data tools. Some hesitation usually remains. Particularly for organizations where the bulk of their existing staff are already familiar with using Excel, where Excel has been tied to a number of critical processes, or where their data challenges are so diverse that no single tool or platform can address all of their needs.
An analytical compromise
So towards that, we've found success in helping several organizations reach an analytical compromise. We say compromise, as we advocate for a solution where organizations can still maintain their existing workflows and continue to operate within Excel. But at the same time, we open the door for their members to use Python directly within Excel.
So how is this made possible? Well, there are several open source libraries available, such as openpyxl, which allow data to be read from Excel into a Python environment. Where it can then be manipulated, modelled, and written back into Excel for consumption. But our preferred solution offers a much closer form of integration. One where users can write and maintain custom Python-based user functions which can be called directly within Excel, and even allow workbooks to be exposed via a REST API, so that they can be accessed and interacted with across the organization's network.
xlwings to the rescue
This is all made possible with xlwings. A light-weight Excel add-in, which allows your custom Python environment to be directly called and used within Excel. Once you are up and running, you can use xlwings to build and expose Python definitions, and return the output of these definitions anywhere within an Excel workbook. Whether that's a custom data handler using pandas, a machine learning workflow to make a prediction using scikit-learn, or to make use of a memory efficient Monte Carlo simulator using numpy.
To get users started, we often make reference to the documentation the xlwings team have pulled together. It walks through everything from how to install and integrate xlwings into Excel, right through to building your first python-based User Defined Function. Or, for those that want a more visual introduction, the xlwings team also provide a set of paid video courses which cover setup, but also a range of common use-cases.
Step 1
Install and setup Anaconda
First, we're going to install and set up our Python environment. And for that, we'll make use of the Anaconda distribution.
Download and Install Anaconda for your OS: Head over to Anaconda's download page and download the installer for your OS. Once you have the installer, follow Anaconda's detailed installation instructions.
Access the Anaconda prompt: The Anaconda installation will have created a base Python environment which you can go ahead and use. But it's often good practice to create and maintain separate environments for specific workflows. So go ahead and open the Anaconda Navigator and then open an Anaconda prompt using the appropriate navigator shortcut.
Create a new Anaconda environment: Anaconda provide some great documentation on how to use their prompt. But for our purposes, we only need to run a few select commands.
First, create a new separate environment named 'Python38', which includes all base Anaconda packages:
conda create -n Python38 python=3.8 anacondaAfter you run that command, let's go ahead and confirm our new 'Python38' environment successfully installed by using the conda env list command:
conda env listYou should see two environments in a format similar to below:
# conda environments:
#
base C:\\Users\\user\\anaconda3
Python38 * C:\\Users\\user\\anaconda3\envs\Python38
There is one entry for your 'base' environment, and the other is for your new 'Python38' environment. The paths represent the installation location for each environment. Do take note of the location of your 'base' environment, as we are going to need this later.
As a handy hint, you can switch between environments using the conda activate and deactivate commands:
conda activate Python38conda deactivate
The currently active environment will appear in brackets before the command line. Similar to:
(Python38) C:\Users\users>_And that's it. You now have a Python distribution installed on your machine, and a fresh environment ready to create your new Python-based workflows.
Step 2
Install and setup the xlwings add-in
xlwings actually comes pre-packaged with the Anaconda distribution. But what Anaconda doesn't include, is the xlwings Excel add-in. This is a must-have if you want to get the most out of xlwings Python-Excel integration and use Python-based definitions directly within your workbooks.
Make a quick change within Excel: We need to make a quick change to our Excel settings before we install the add-in. And fortunately, the xlwings documentation spells this change out clearly. But in short, you need to enable 'Trust membership to the VBA project object model' under the 'Macro Settings' of the 'Trust Center'. Once you have that enabled, you can go ahead and close Excel.
Install the xlwings add-in: Now, go ahead and open a new Anaconda command prompt (unless you left it open from earlier). And activate your 'Python38' environment using the 'conda activate' command. Once activated, simply run the following command to install the add-in:
xlwings add-in installIf successful, you should see a prompt similar to "Successfully installed the xlwings add-in! Please restart Excel". Which is your queue to go ahead and re-open Excel.
Configure the xlwings add-in: When you next open an Excel workbook, you should be greeted by the 'xlwings' option within your Excel menu. Now, there are some entries we will need to confirm via the xlwings menu. In particular, you need to confirm that the 'Conda Path' field includes the path to the 'base' environment location you noted during the previous step. And the 'Conda Env' field has 'Python38' entered. This will ensure xlwings leverages your newly created environment. Once confirmed, go ahead and close Excel for the second time.
Step 3
Start a new xlwings project
Next, we're going to create an xlwings project. Which, quite simply, is a new folder which includes a blank Excel (.xlsx) workbook and Python (.py) file. Note that these files must have the same filename so they may interact with each other via xlwings.
Start your new xlwings project: Go ahead and open a new Anaconda command prompt once again (unless you left it open from earlier) and activate your 'Python38' environment using the 'conda activate' command. Once activated, browse to your desired working location and run the following command after replacing 'myproject' with your desired project name:
xlwings quickstart myprojectThis should automatically create a new folder in your working location, with the .xlsx and .py files you need.
Open and check your project files: Open the Excel workbook within your project folder and 'Enable Macros' if Excel prompts you. Then go ahead and open the Python .py file from the same folder using a plain text editor. The Python file should have a couple of example definitions to get you started. One of which, will be a 'main()' function. This function will run every time you press the 'Run main' button within the xlwings menu. And then there is the 'hello()' function. Notice that this function includes an '@xw.func' decorator above it. Which means that it will be made available for you to use within Excel after you press the 'Import functions' button.
Test the integration: To test the integration, first press the 'Run main' button within the xlwings menu. The 'main()' function should run, and you should see 'Hello xlwings!' appear in cell A1 on Sheet1. Nice. Next, press the 'Import functions' button, and type '=hello("Bill")' as a formula into cell A2. You should see 'Hello Bill!' appear confirming that Excel has called your simple 'hello()' function.
If you like, try making a slight change to the 'hello()' function:
@xw.func
def hello(first_name, last_name):
return f"Hello !"
Then re-import the function, and type '=hello("Billie", "Jean")' as a formula into cell A2. You should see 'Hello Billie Jean!' appear.
Step 4
Use a decision tree model within Excel
It's now time to build and run a simple data science workflow using our Python-Excel integration. We say simple, however this will be the most involved part of the post. So keep patient and work through each step slowly.
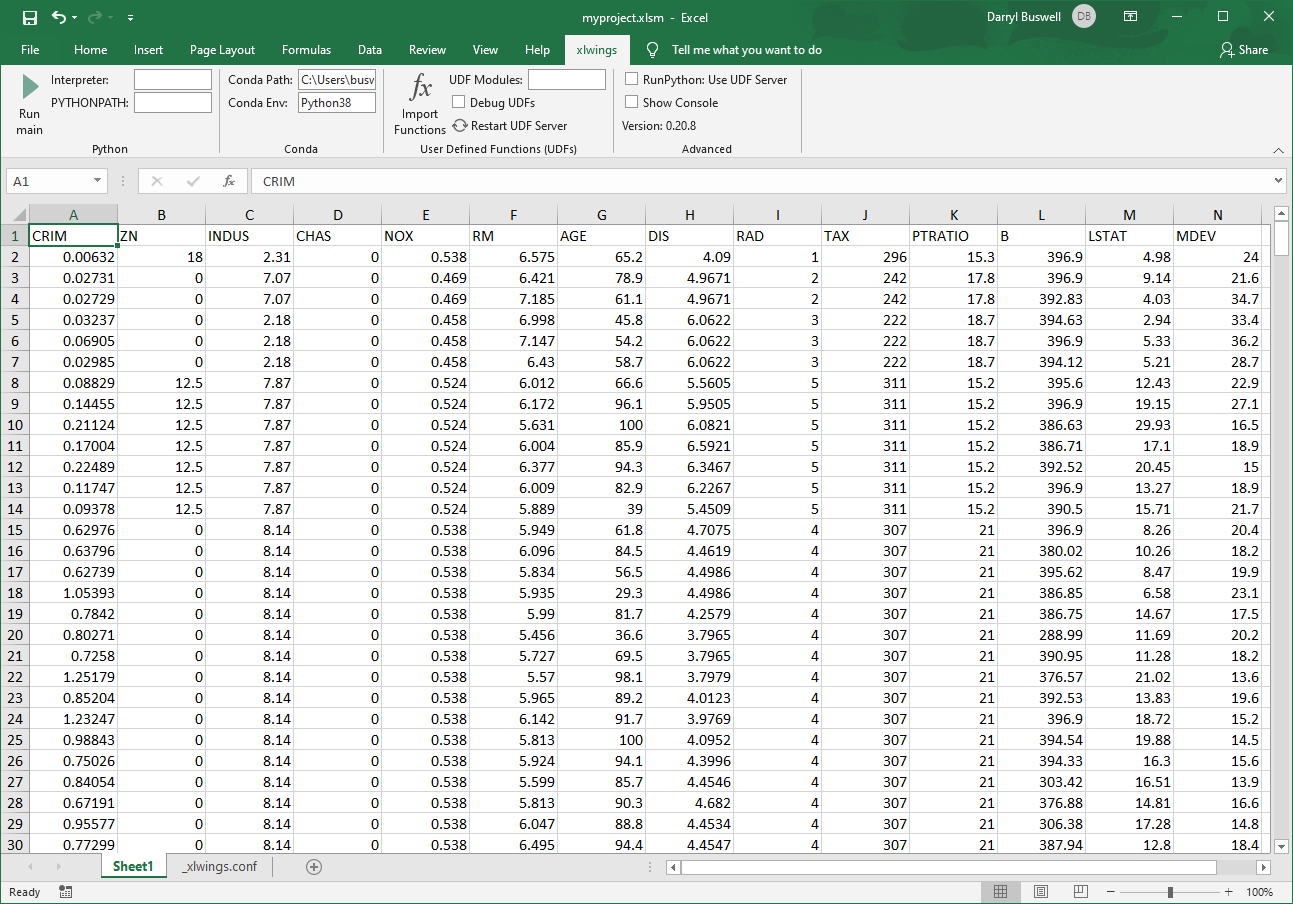
Copy the dataset into Excel: Head over to our codebook repository and open the Boston house price dataset. Copy the full set of data and paste it into column A within your Excel workbook. You'll need to use Excels 'text-to-columns' feature within the 'Data' tab, and use a comma delimiter, in order to separate the data out into distinct columns. If successful, you should have a full array of data spanning A1:N507.
Observe the dataset: Before we jump into creating our model function, take some time to look over the dataset. In particular, take note of the feature columns (i.e. your input columns). This includes every column from 'CRIM' right through to 'LSTAT', and will be used by your model to make a prediction. Then note the label (i.e. your output column), 'MDEV', which is made up of a set of scaled house prices.
Create a decision tree model function: Open your Python .py file and paste the following block of code as a new function. Then save the file and re-import your functions via the xlwings menu:
import numpy as np
from sklearn.tree import DecisionTreeRegressor
@xw.func
@xw.arg('X_train', np.array, ndim=2)
@xw.arg('y_train', np.array, ndim=2)
@xw.arg('X_new', np.array, ndim=2)
def pred_dtr(X_train, y_train, X_new):
clf = DecisionTreeRegressor()
clf.fit(X_train, y_train)
# model validation of test vs train set here
y_pred = clf.predict(X=X_new)
return y_pred
Do recognize that we are omitting some critical model development steps here for the sake of simplicity. Specifically, we are not making a training versus test split, nor are we following a process to validate our model fit. Instead, we are simply going to train our decision tree on all but the last row of data and then make a prediction using the feature columns of the last row. The result from our call to the model function should be a single value, representing a prediction of the house price for the final row. Which we can then manually compare to the actual house price value for the same row.
Fit the decision tree regressor: Go ahead and scroll down to the last row of the dataset and select cell A507. The selected cell should line up with the actual house price value which we are looking to predict. Next, enter the following into the formula bar: '=pred_dtr(A2:M506,N2:N506,A507:M507)'. The first and second array represent the feature and label data, which we will use to train our model. While the third array represents the feature data for the final record we are looking to predict. If it all goes well, the function should return a single value for comparison.
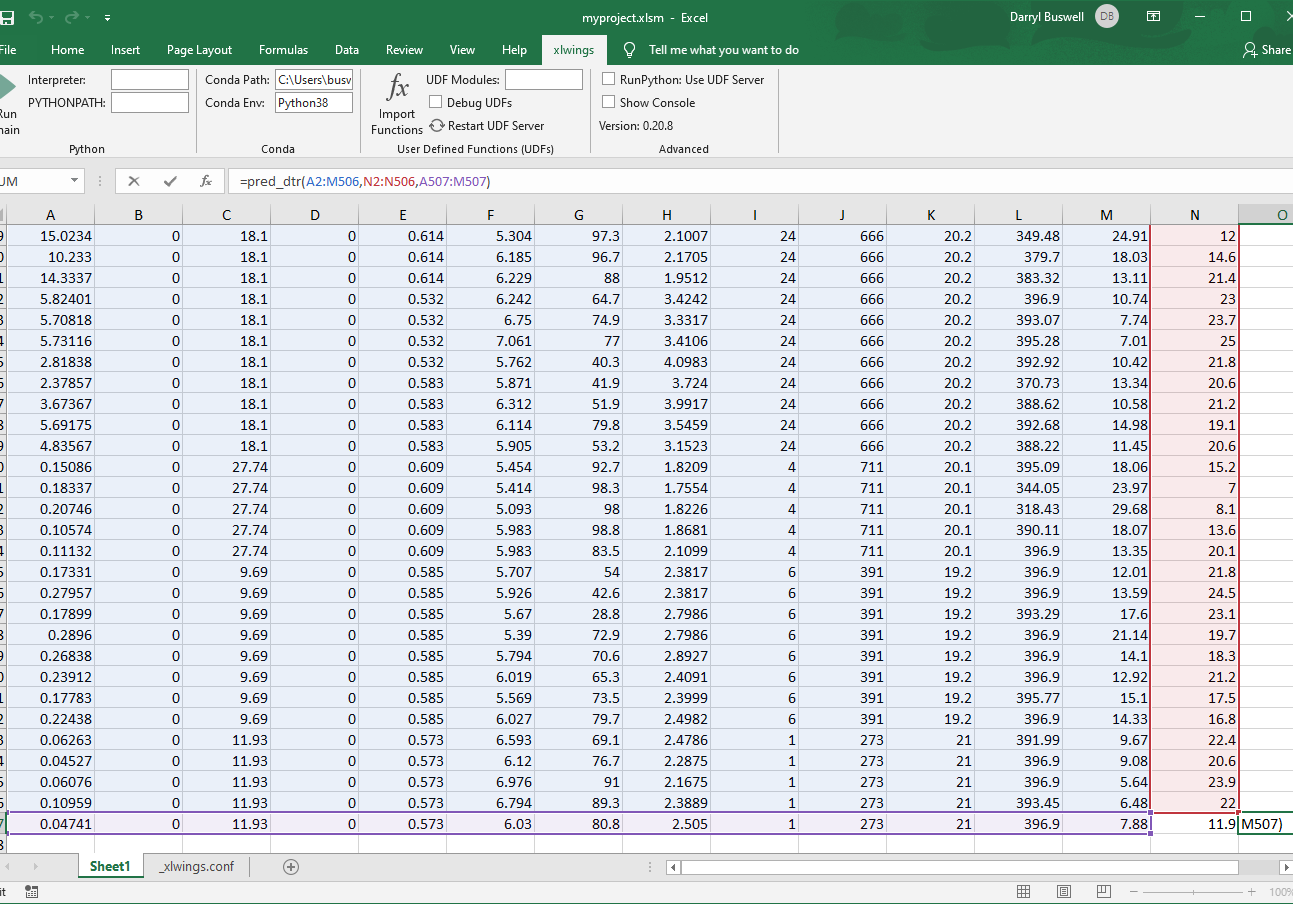
Congratulations you have proved-out the simple model function and integration.
Start experimenting: Go ahead and start building on the model function. You'll likely want to make a proper train versus test split, limit the complexity (e.g. depth) of the tree, as well as expand the function results to include a set of validation metrics.
Well done! You're now up and running with Excel and Python. And with that, you have unlocked a new world of capability. We highly recommend you check out the workflow examples provided on the xlwings homepage. Then, as a challenge, take a stab at replacing some functionality within some of your more bloated workbooks. You'll no doubt find a lot of utility using packages such as pandas for some of your more intensive data manipulation tasks, and numpy for any heavy statistical modelling.